
Data to decisions in real-time with reduced models: modeling contaminant release on the MIT campus.
Funded by U.S. Department of Energy Mathematical Multifaceted Integrated Capabilities Center (MMICC) · Program Manager Steven Lee
Project Site dmd.mit.eduRelevant publications
The Department of Energy (DOE) MMICC DiaMonD project develops mathematical methods and analysis at the interfaces of data, models and decisions, with a focus on multimodel, multiphysics, multiscale model problems driven by frontier DOE applications. The MIT part of the DiaMonD team is developing methods for multifidelity inverse problem solution, multifidelity uncertainty quantification, and goal-oriented adaptive multi-model management.
Peherstorfer, B., Gunzburger, M., and Willcox, K., Numerische Mathematik, 139(3):683-707, 2018., https://doi.org/10.1007/s00211-018-0945-7.
The multifidelity Monte Carlo method provides a general framework for combining cheap low-fidelity approximations of an expensive high-fidelity model to accelerate the Monte Carlo estimation of statistics of the high-fidelity model output. In this work, we investigate the properties of multifidelity Monte Carlo estimation in the setting where a hierarchy of approximations can be constructed with known error and cost bounds. Our main result is a convergence analysis of multifidelity Monte Carlo estimation, for which we prove a bound on the costs of the multifidelity Monte Carlo estimator under assumptions on the error and cost bounds of the low-fidelity approximations. The assumptions that we make are typical in the setting of similar Monte Carlo techniques. Numerical experiments illustrate the derived bounds.
Peherstorfer, B., Willcox, K. and Gunzburger, M., SIAM Review, Vol. 60, No. 3, pp. 550-591, 2018.
In many situations across computational science and engineering, multiple computational models are available that describe a system of interest. These different models have varying evaluation costs and varying fidelities. Typically, a computationally expensive high-fidelity model describes the system with the accuracy required by the current application at hand, while lower-fidelity models are less accurate but computationally cheaper than the high-fidelity model. Outer-loop applications, such as optimization, inference, and uncertainty quantification, require multiple model evaluations at many different inputs, which often leads to computational demands that exceed available resources if only the high-fidelity model is used. This work surveys multifidelity methods that accelerate the solution of outer-loop applications by combining high-fidelity and low-fidelity model evaluations, where the low-fidelity evaluations arise from an explicit low-fidelity model (e.g., a simplified physics approximation, a reduced model, a data-fit surrogate, etc.) that approximates the same output quantity as the high-fidelity model. The overall premise of these multifidelity methods is that low-fidelity models are leveraged for speedup while the high-fidelity model is kept in the loop to establish accuracy and/or convergence guarantees. We categorize multifidelity methods according to three classes of strategies: adaptation, fusion, and filtering. The paper reviews multifidelity methods in the outer-loop contexts of uncertainty propagation, inference, and optimization.
Singh, V. and Willcox, K. Accepted, AIAA Journal, 2018.
Digital Thread is a data-driven architecture that links together information generated from across the product lifecycle. A specific opportunity is to leverage Digital Thread to more efficiently design the next generation of products. This task is a data-driven design and decision problem under uncertainty. This paper explores this problem through three objectives: 1) Provide a mathematical definition of Digital Thread in the context of a specific engineering design problem. 2) Establish the feedback coupling of how information from Digital Thread enters the design problem. 3) Develop a data-driven design methodology that incorporates information from Digital Thread into the next generation of product designs. The methodology is illustrated through an example design of a structural fiber steered composite component.
Li, H., Garg, V. and Willcox, K., Computer Methods in Applied Mechanics and Engineering, Vol. 331, pp. 1-22, April 2018.
An inverse problem seeks to infer unknown model parameters using observed data. We consider a goal-oriented inverse problem , where the goal of inferring parameters is to use them in predicting a quantity of interest (QoI). Recognizing that multiple models of varying fidelity and computational cost may be available to describe the physical system, we formulate a goal-oriented model adaptivity approach that leverages multiple models while controlling the error in the QoI prediction. In particular, we adaptively form a mixed-fidelity model by using models of different levels of fidelity in different subregions of the domain. Taking the solution of the inverse problem with the highest-fidelity model as our reference QoI prediction, we derive an adjoint-based third-order estimate for the QoI error from using a lower-fidelity model. Localization of this error then guides the formation of mixed-fidelity models. We demonstrate the method for example problems described by convection-diffusion-reaction models. For these examples, our mixed-fidelity models use the high-fidelity model over only a small portion of the domain, but result in QoI estimates with small relative errors. We also demonstrate that the mixed-fidelity inverse problems can be cheaper to solve and less sensitive to the initial guess than the high-fidelity inverse problems.
Qian, E., Peherstorfer, B., O'Malley, D., Vesselinov, V. and Willcox, K., SIAM/ASA Journal on Uncertainty Quantification, 6 (2): 683-706, 2018.
Variance-based sensitivity analysis provides a quantitative measure of how uncertainty in a model input contributes to uncertainty in the model output. Such sensitivity analyses arise in a wide variety of applications and are typically computed using Monte Carlo estimation, but the many samples required for Monte Carlo to be sufficiently accurate can make these analyses intractable when the model is expensive. This work presents a multifidelity approach for estimating sensitivity indices that leverages cheaper low-fidelity models to reduce the cost of sensitivity analysis while retaining accuracy guarantees via recourse to the original, expensive model. This paper develops new multifidelity estimators for variance and for the Sobol’ main and total effect sensitivity indices. We discuss strategies for dividing limited computational resources among models and specify a recommended strategy. Results are presented for the Ishigami function and a convection-diffusion-reaction model that demonstrate up to 10 times speedups for fixed convergence levels. For the problems tested, the multifidelity approach allows inputs to be definitively ranked in importance when Monte Carlo alone fails to do so.
Zimmermann, R., Peherstorfer, B. and Willcox, K., SIAM Journal on Matrix Analysis and Applications, Vol. 39, No. 1, pp. 234-261, 2018.
In many scientific applications, including model reduction and image processing, subspaces are used as ansatz spaces for the low-dimensional approximation and reconstruction of the state vectors of interest. We introduce a procedure for adapting an existing subspace based on information from the least-squares problem that underlies the approximation problem of interest such that the associated least-squares residual vanishes exactly. The method builds on a Riemmannian optimization procedure on the Grassmann manifold of low-dimensional subspaces, namely the Grassmannian Rank-One Update Subspace Estimation (GROUSE). We establish for GROUSE a closed-form expression for the residual function along the geodesic descent direction. Specific applications of subspace adaptation are discussed in the context of image processing and model reduction of nonlinear partial differential equation systems.
Kramer, B., Marques, A., Peherstorfer, B., Villa, U. and Willcox, K., ACDL TR-2017-3, Submitted, 2017
This paper develops a multifidelity method that enables estimation of failure probabilities for expensive-to-evaluate models via a new combination of techniques, drawing from information fusion and importance sampling. We use low-fidelity models to derive biasing densities for importance sampling and then fuse the importance sampling estimators such that the fused multifidelity estimator is unbiased and has mean-squared error lower than or equal to that of any of the importance sampling estimators alone. The presented general fusion method combines multiple probability estimators with the goal of further variance reduction. By fusing all available estimators, the method circumvents the challenging problem of selecting the best biasing density and using only that density for sampling. A rigorous analysis shows that the fused estimator is optimal in the sense that it has minimal variance amongst all possible combinations of the estimators. The asymptotic behavior of the proposed method is demonstrated on a convection-diffusion-reaction PDE model for which n=1.e5 samples can be afforded. To illustrate the proposed method at scale, we consider a model of a free plane jet and quantify how uncertainties at the flow inlet propagate to a quantity of interest related to turbulent mixing. The computed fused estimator has similar root-mean-squared error to that of an importance sampling estimator using a density computed from the high-fidelity model. However, it reduces the CPU time to compute the biasing density from 2.5 months to three weeks.
Kramer, B., Peherstorfer, B. and Willcox, K., SIAM Journal on Applied Dynamical Systems, Vol. 16, No. 3, pp. 1563-1586, 2017.
We consider control and stabilization for large-scale dynamical systems with uncertain, time-varying parameters. The time-critical task of controlling a dynamical system poses major challenges: using large-scale models is prohibitive, and accurately inferring parameters can be expensive, too. We address both problems by proposing an offline-online strategy for controlling systems with time-varying parameters. During the offline phase, we use a high-fidelity model to compute a library of optimal feedback controller gains over a sampled set of parameter values. Then, during the online phase, in which the uncertain parameter changes over time, we learn a reduced-order model from system data. The learned reduced-order model is employed within an optimization routine to update the feedback control throughout the online phase. Since the system data naturally reflects the uncertain parameter, the data-driven updating of the controller gains is achieved without an explicit parameter estimation step. We consider two numerical test problems in the form of partial differential equations: a convection-diffusion system, and a model for flow through a porous medium. We demonstrate on those models that the proposed method successfully stabilizes the system model in the presence of process noise.
Spantini, A., Cui, T., Willcox, K., Tenorio, L. and Marzouk, Y. SIAM Journal on Scientific Computing, Vol. 39, No. 5 pp. S167-S196, 2017.
We propose optimal dimensionality reduction techniques for the solution of goal–oriented linear–Gaussian inverse problems, where the quantity of interest (QoI) is a function of the inversion parameters. These approximations are suitable for large-scale applications. In particular, we study the approx- imation of the posterior covariance of the QoI as a low-rank negative update of its prior covariance, and prove optimality of this update with respect to the natural geodesic distance on the manifold of symmetric positive definite matrices. Assuming exact knowledge of the posterior mean of the QoI, the optimality re- sults extend to optimality in distribution with respect to the Kullback-Leibler divergence and the Hellinger distance between the associated distributions. We also propose the approximation of the posterior mean of the QoI as a low-rank linear function of the data, and prove optimality of this approximation with respect to a weighted Bayes risk. Both of these optimal approximations avoid the explicit computation of the full posterior distribution of the parameters and instead focus on directions that are well informed by the data and relevant to the QoI. These directions stem from a balance among all the components of the goal–oriented inverse problem: prior information, forward model, measurement noise, and ultimate goals. We illustrate the theory using a high-dimensional inverse problem in heat transfer.
Cui, T., Marzouk, Y. and Willcox, K., Journal of Computational Physics, 315, 363-387, 2016.
Two major bottlenecks to the solution of large-scale Bayesian inverse problems are the scaling of posterior sampling algorithms to high-dimensional parameter spaces and the computational cost of forward model evaluations. Yet incomplete or noisy data, the state variation and parameter dependence of the forward model, and correlations in the prior collectively provide useful structure that can be exploited for dimension reduction in this setting—both in the parameter space of the inverse problem and in the state space of the forward model. To this end, we show how to jointly construct low-dimensional subspaces of the parameter space and the state space in order to accelerate the Bayesian solution of the inverse problem. As a byproduct of state dimension reduction, we also show how to identify low-dimensional subspaces of the data in problems with high-dimensional observations. These subspaces enable approximation of the posterior as a product of two factors: (i) a projection of the posterior onto a low-dimensional parameter subspace, wherein the original likelihood is replaced by an approximation involving a reduced model; and (ii) the marginal prior distribution on the high-dimensional complement of the parameter subspace. We present and compare several strategies for constructing these subspaces using only a limited number of forward and adjoint model simulations. The resulting posterior approximations can rapidly be characterized using standard sampling techniques, e.g., Markov chain Monte Carlo. Two numerical examples demonstrate the accuracy and efficiency of our approach: inversion of an integral equation in atmospheric remote sensing, where the data dimension is very high; and the inference of a heterogeneous transmissivity field in a groundwater system, which involves a partial differential equation forward model with high dimensional state and parameters.
Opgenoord, M., Allaire, D. and Willcox, K., Journal of Mechanical Design, Vol. 138, No. 11, pp. 111410-111410-12, 2016.
Sensitivity analysis plays a critical role in quantifying uncertainty in the design of engineering systems. A variance-based global sensitivity analysis is often used to rank the importance of input factors, based on their contribution to the variance of the output quantity of interest. However, this analysis assumes that all input variability can be reduced to zero, which is typically not the case in a design setting. Distributional sensitivity analysis (DSA) instead treats the uncertainty reduction in the inputs as a random variable, and defines a variance-based sensitivity index function that characterizes the relative contribution to the output variance as a function of the amount of uncertainty reduction. This paper develops a computationally efficient implementation for the DSA formulation and extends it to include distributions commonly used in engineering design under uncertainty. Application of the DSA method to the conceptual design of a commercial jetliner demonstrates how the sensitivity analysis provides valuable information to designers and decision-makers on where and how to target uncertainty reduction efforts.
Peherstorfer, B. and Willcox, K., Advanced Modeling and Simulation in Engineering Sciences, Vol. 3, Issue 1, 2016.
This work presents a data-driven online adaptive model reduction approach for systems that undergo dynamic changes. Classical model reduction constructs a reduced model of a large-scale system in an offline phase and then keeps the reduced model unchanged during the evaluations in an online phase; however, if the system changes online, the reduced model may fail to predict the behavior of the changed system. Rebuilding the reduced model from scratch is often too expensive in time-critical and real-time environments. We introduce a dynamic data-driven adaptation approach that adapts the reduced model from incomplete sensor data obtained from the system during the online computations. The updates to the reduced models are derived directly from the incomplete data, without recourse to the full model. Our adaptivity approach approximates the missing values in the incomplete sensor data with gappy proper orthogonal decomposition. These approximate data are then used to derive low-rank updates to the reduced basis and the reduced operators. In our numerical examples, incomplete data with 30-40% known values are sufficient to recover the reduced model that would be obtained via rebuilding from scratch.
Peherstorfer, B., Cui, T., Marzouk, Y. and Willcox, K., Computer Methods in Applied Mechanics and Engineering, Vol. 300, pp. 490-509, 2016.
Estimating statistics of model outputs with the Monte Carlo method often requires a large number of model evaluations. This leads to long runtimes if the model is expensive to evaluate. Importance sampling is one approach that can lead to a reduction in the number of model evaluations. Importance sampling uses a biasing distribution to sample the model more efficiently, but generating such a biasing distribution can be difficult and usually also requires model evaluations. A different strategy to speed up Monte Carlo sampling is to replace the computationally expensive high-fidelity model with a computationally cheap surrogate model; however, because the surrogate model outputs are only approximations of the high-fidelity model outputs, the estimate obtained using a surrogate model is in general biased with respect to the estimate obtained using the high-fidelity model. We introduce a multifidelity importance sampling (MFIS) method, which combines evaluations of both the high-fidelity and a surrogate model. It uses a surrogate model to facilitate the construction of the biasing distribution, but relies on a small number of evaluations of the high-fidelity model to derive an unbiased estimate of the statistics of interest. We prove that the MFIS estimate is unbiased even in the absence of accuracy guarantees on the surrogate model itself. The MFIS method can be used with any type of surrogate model, such as projection-based reduced-order models and data-fit models. Furthermore, the MFIS method is applicable to black-box models, i.e., where only inputs and the corresponding outputs of the high-fidelity and the surrogate model are available but not the details of the models themselves. We demonstrate on nonlinear and time-dependent problems that our MFIS method achieves speedups of up to several orders of magnitude compared to Monte Carlo with importance sampling that uses the high-fidelity model only.
Peherstorfer, B. and Willcox, K., Computer Methods in Applied Mechanics and Engineering, Vol. 306, pp. 196-215, 2016.
This work presents a nonintrusive projection-based model reduction approach for full models based on time-dependent partial differential equations. Projection-based model reduction constructs the operators of a reduced model by projecting the equations of the full model onto a reduced space. Traditionally, this projection is intrusive, which means that the full-model operators are required either explicitly in an assembled form or implicitly through a routine that returns the action of the operators on a given vector; however, in many situations the full model is given as a black box that computes trajectories of the full-model states and outputs for given initial conditions and inputs, but does not provide the full-model operators. Our nonintrusive operator inference approach infers approximations of the reduced operators from the initial conditions, inputs, trajectories of the states, and outputs of the full model, without requiring the full-model operators. Our operator inference is applicable to full models that are linear in the state or have a low-order polynomial nonlinear term. The inferred operators are the solution of a least-squares problem and converge, with sufficient state trajectory data, in the Frobenius norm to the reduced operators that would be obtained via an intrusive projection of the full-model operators. Our numerical results demonstrate operator inference on a linear climate model and on a tubular reactor model with a polynomial nonlinear term of third order.
Peherstorfer, B., Willcox, K. and Gunzburger, M., SIAM Journal on Scientific Computing, Vol. 38, No. 5, pp. A3163-A3194, 2016.
This work presents an optimal model management strategy that exploits multifidelity surrogate models to accelerate the estimation of statistics of outputs of computationally expensive high-fidelity models. Existing acceleration methods typically exploit a multilevel hierarchy of surrogate models that follow a known rate of error decay and computational costs; however, a general collection of surrogate models, which may include projection-based reduced models, data-fit models, support vector machines, and simplified-physics models, does not necessarily give rise to such a hierarchy. Our multifidelity approach provides a framework to combine an arbitrary number of surrogate models of any type. Instead of relying on error and cost rates, an optimization problem balances the number of model evaluations across the high-fidelity and surrogate models with respect to error and costs. We show that a unique analytic solution of the model management optimization problem exists under mild conditions on the models. Our multifidelity method makes occasional recourse to the high-fidelity model; in doing so it provides an unbiased estimator of the statistics of the high-fidelity model, even in the absence of error bounds and error estimators for the surrogate models. Numerical experiments with linear and nonlinear examples show that speedups by orders of magnitude are obtained compared to Monte Carlo estimation that invokes a single model only.
Qian, E., Grepl, M., Veroy, K., and Willcox, K., SIAM Journal on Scientific Computing, Vol. 39, No. 5 pp. S434-S460, 2017.
Parameter optimization problems constrained by partial differential equations (PDEs) appear in many science and engineering applications. Solving these optimization problems may require a prohibitively large number of computationally expensive PDE solves, especially if the dimension of the design space is large. It is therefore advantageous to replace expensive high-dimensional PDE solvers (e.g., finite element) with lower-dimension surrogate models. In this paper, the reduced basis (RB) model reduction method is used in conjunction with a trust region opti- mization framework to accelerate PDE-constrained parameter optimization. Novel a posteriori error bounds on the RB cost and cost gradient for quadratic cost functionals (e.g., least squares) are presented, and used to guarantee convergence to the optimum of the high-fidelity model. The proposed certified RB trust region approach uses high-fidelity solves to update the RB model only if the approximation is no longer sufficiently accurate, reducing the number of full-fidelity solves required. We consider problems governed by elliptic and parabolic PDEs and present numerical results for a thermal fin model problem in which we are able to reduce the number of full solves necessary for the optimization by up to 86%.
Zimmermann, R. and Willcox, K., SIAM Journal on Scientific Computing, Vol. 38, Issue 5, pp. A2827–A2850, 2016.
Model reduction via Galerkin projection fails to provide considerable computational savings if applied to general nonlinear systems. This is because the reduced representation of the state vector appears as an argument to the nonlinear function, whose evaluation remains as costly as for the full model. Masked projection approaches, such as the missing point estimation and the (discrete) empirical interpolation method, alleviate this effect by evaluating only a small subset of the components of a given nonlinear term; however, the selection of the evaluated components is a combinatorial problem and is computationally intractable even for systems of small size. This has been addressed through greedy point selection algorithms, which minimize an error indicator by sequentially looping over all components. While doable, this is sub optimal and still costly. This paper introduces an approach to accelerate and improve the greedy search. The method is based on the observation that the greedy algorithm requires solving a sequence of symmetric rank-one modifications to an eigenvalue problem. For doing so, we develop fast approximations that sort the set of candidate vectors that induce the rank-one modifications, without requiring solution of the modified eigenvalue problem. Based on theoretical insights into symmetric rank-one eigenvalue modifications, we derive a variation of the greedy method that is faster than the standard approach and yields better results for the cases studied. The proposed approach is illustrated by numerical experiments, where we observe a speed-up by two orders of magnitude when compared to the standard greedy method while arriving at a better quality reduced model.
Garg, V., Tenorio, L. and Willcox, K., Communications in Statistics — Theory and Methods, Vol. 46, No. 1, 148-164, 2016.
We present a local density estimator based on first order statistics. To estimate the density at a point, x, the original sample is divided into subsets and the average minimum sample distance to x over all such subsets is used to define the density estimate at x. The tuning parameter is thus the number of subsets instead of the typical bandwidth of kernel or histogram-based density estimators. The proposed method is similar to nearest-neighbor density estimators but it provides smoother estimates. We derive the asymptotic distribution of this minimum sample distance statistic to study globally optimal values for the number and size of the subsets. Simulations are used to illustrate and compare the convergence properties of the estimator. The results show that the method provides good estimates of a wide variety of densities without changes of the tuning parameter, and that it offers competitive convergence performance.
Cui, T., Marzouk, Y. and Willcox, K., International Journal for Numerical Methods in Engineering, Vol. 102, No. 5, pp. 966-990, published online 15 August, 2014, DOI: 10.1002/nme.4748.
One of the major challenges in the Bayesian solution of inverse problems governed by partial differential equations (PDEs) is the computational cost of repeatedly evaluating numerical PDE models, as required by Markov chain Monte Carlo (MCMC) methods for posterior sampling. This paper proposes a data-driven projection-based model reduction technique to reduce this computational cost. The proposed technique has two distinctive features. First, the model reduction strategy is tailored to inverse problems: the snapshots used to construct the reduced-order model are computed adaptively from the posterior distribution. Posterior exploration and model reduction are thus pursued simultaneously. Second, to avoid repeated evaluations of the full-scale numerical model as in a standard MCMC method, we couple the full-scale model and the reduced-order model together in the MCMC algorithm. This maintains accurate inference while reducing its overall computational cost. In numerical experiments considering steady-state flow in a porous medium, the data-driven reduced-order model achieves better accuracy than a reduced-order model constructed using the classical approach. It also improves posterior sampling efficiency by several orders of magnitude compared with a standard MCMC method.
Lieberman, C. and Willcox, K., SIAM Journal on Scientific Computing, Vol. 36, No. 3, pp. B427-B449, 2014.
In many engineering problems, unknown parameters of a model are inferred in order to make predictions, to design controllers, or to optimize the model. When parameters are distributed (continuous) or very high-dimensional (discrete) and quantities of interest are low-dimensional, parameters need not be fully resolved to make accurate estimates of quantities of interest. In this work, we extend goal-oriented inference—the process of estimating predictions from observed data without resolving the parameter, previously justified theoretically in the linear setting—to Bayesian statistical inference problem formulations with nonlinear experimental and prediction processes. We propose to learn the joint density of data and predictions offline using Gaussian mixture models. When data are observed online, we condition the representation to arrive at a probabilistic description of predictions given observed data. Our approach enables real-time estimation of uncertainty in quantities of interest and renders tractable high-dimensional PDE-constrained Bayesian inference when there exist low-dimensional output quantities of interest. We demonstrate the method on a realistic problem in carbon capture and storage for which existing methods of Bayesian parameter estimation are intractable.
Lieberman, C., Fidkowski, K, Willcox, K. and van Bloemen Waanders, B., International Journal of Numerical Methods in Fluids, Vol. 71, pp. 135-150, January 2013.
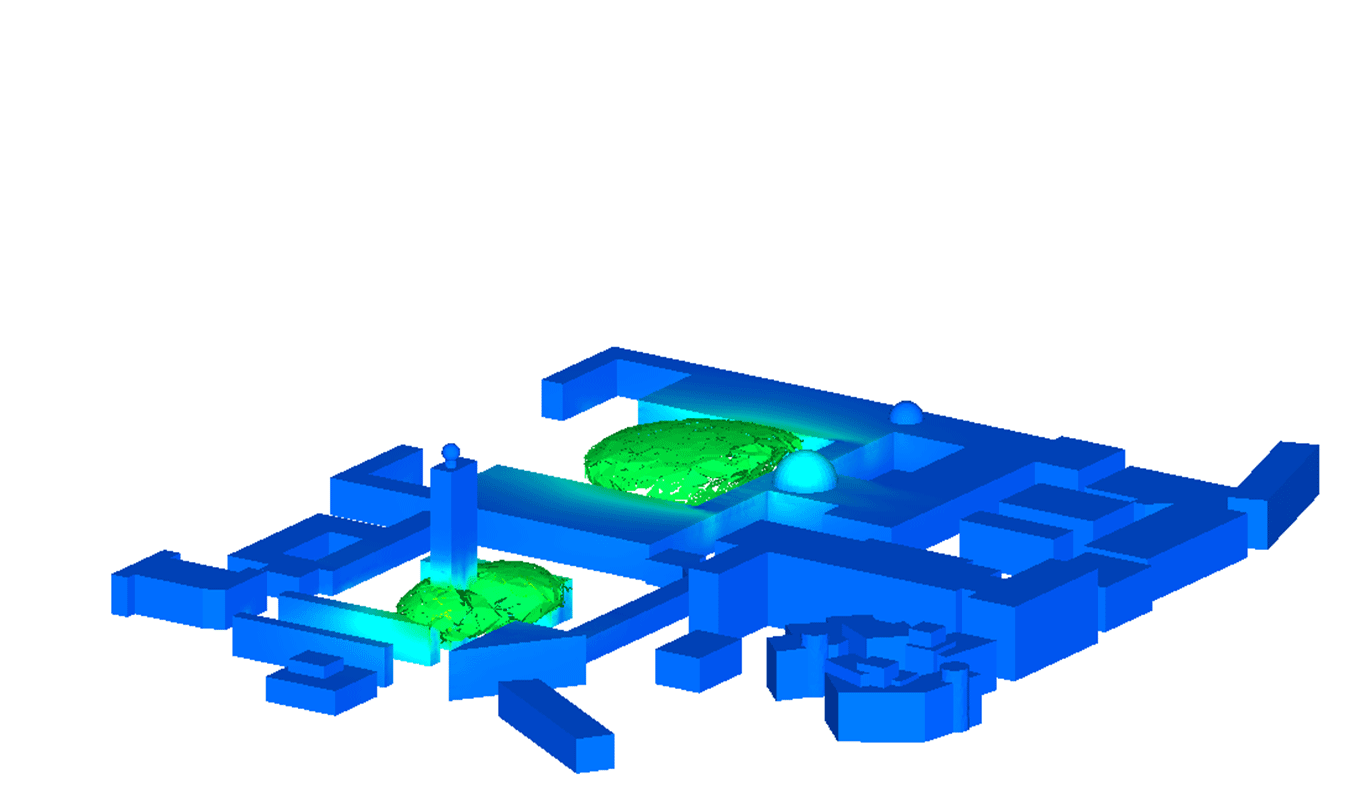
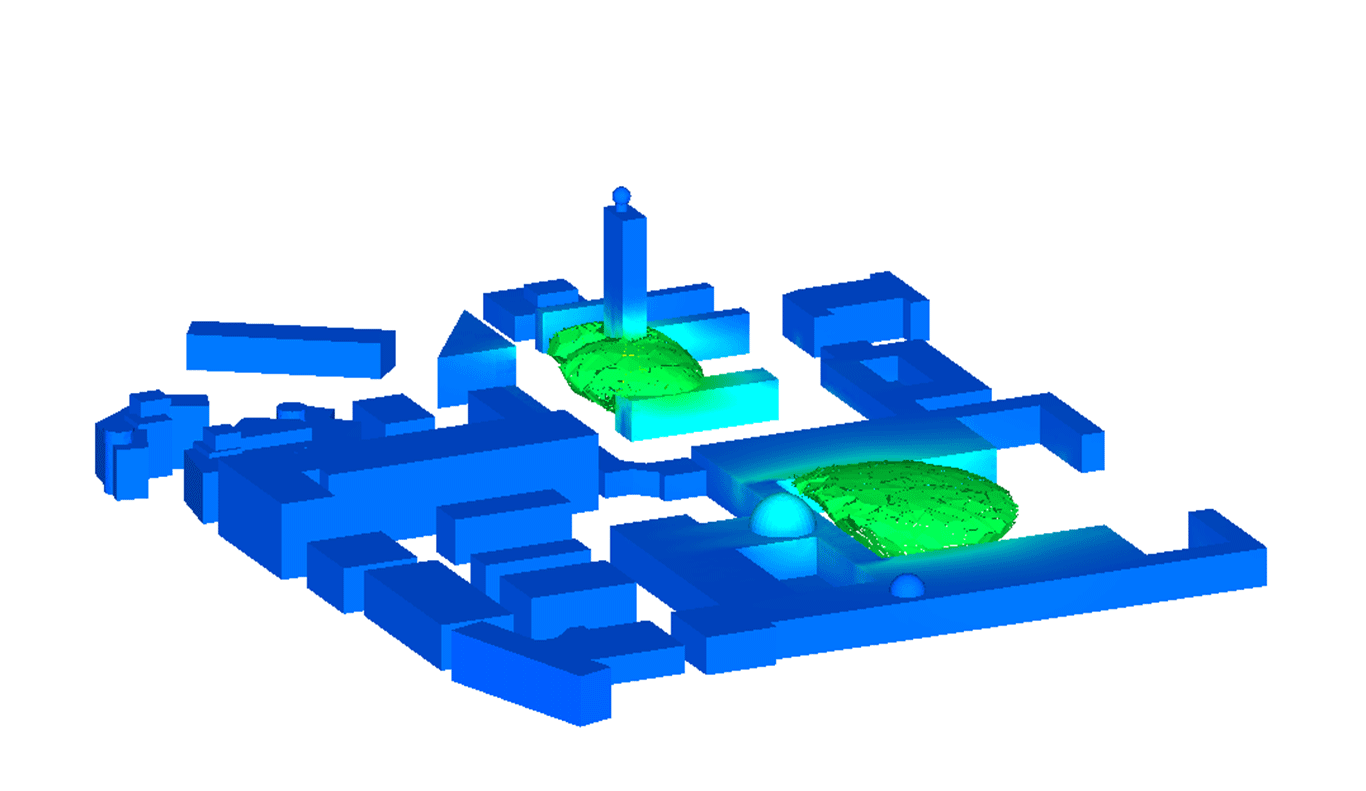
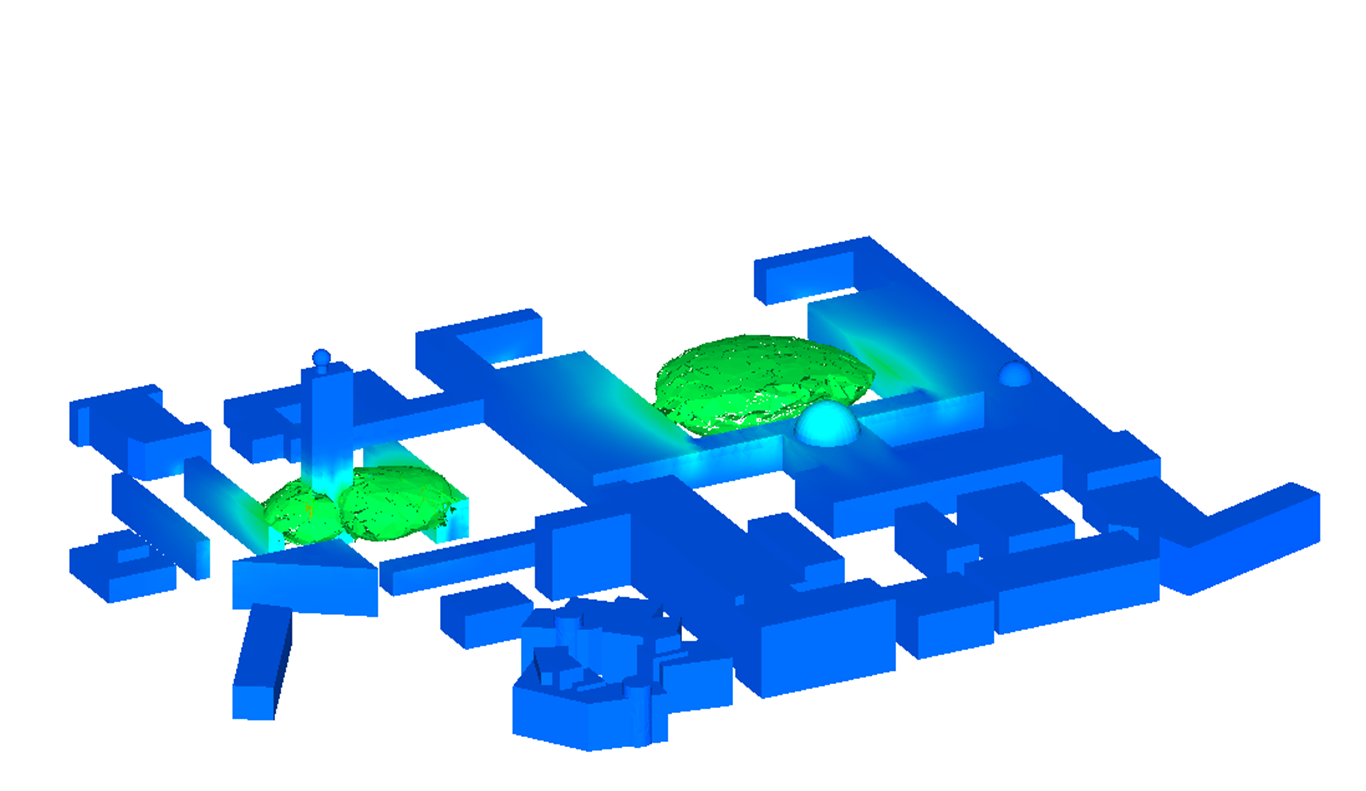
Hessian-based model reduction was previously proposed as an approach in deriving reduced models for the solution of large-scale linear inverse problems by targeting accuracy in observation outputs. A control-theoretic view of Hessian-based model reduction that hinges on the equality between the Hessian and the transient observability gramian of the underlying linear system is presented. The model reduction strategy is applied to a large-scale three-dimensional contaminant transport problem in an urban environment, an application that requires real-time computation. In addition to the inversion accuracy, the ability of reduced models of varying dimension to make predictions of the contaminant evolution beyond the time horizon of observations is studied. Results indicate that the reduced models have a factor 1000 speedup in computing time for the same level of accuracy.
Lieberman, C., and Willcox, K., SIAM Review, 55-3, 493--519, 2013.
Inference of model parameters is one step in an engineering process often ending in predictions that support decision in the form of design or control. Incorporation of end goals into the inference process leads to more efficient goal-oriented algorithms that automatically target the most relevant parameters for prediction. In the linear setting the control-theoretic concepts underlying balanced truncation model reduction can be exploited in inference through a dimensionally optimal subspace regularizer. The inference-for-prediction method exactly replicates the prediction results of either truncated singular value decomposition, Tikhonov-regularized, or Gaussian statistical inverse problem formulations independent of data; it sacrifices accuracy in parameter estimate for online efficiency. The new method leads to low-dimensional parameterization of the inverse problem enabling solution on smartphones or laptops in the field.