
Uncertainty quantification (UQ) involves the quantitative characterization and management of uncertainty in a broad range of applications. It employs both computational models and observational data, together with theoretical analysis. UQ encompasses many different tasks, including uncertainty propagation, sensitivity analysis, statistical inference and model calibration, decision making under uncertainty, experimental design, and model validation. Multifidelity UQ is the use of multiple approximate models and other sources of information to accelerate the UQ task.
Multifidelity UQ methods leverage low-fidelity models to obtain computational speedups in solving UQ tasks. Rather than just replacing the high-fidelity model with a low-fidelity surrogate, multifidelity UQ methods use recourse to the high-fidelity model to establish accuracy and/or convergence guarantees on the UQ result.
Read our recent survey review paper: Peherstorfer, B., Willcox, K. and Gunzburger, M., Survey of multifidelity methods in uncertainty propagation, inference, and optimization, SIAM Review, Vol. 60, No. 3, pp. 550-591, 2018.
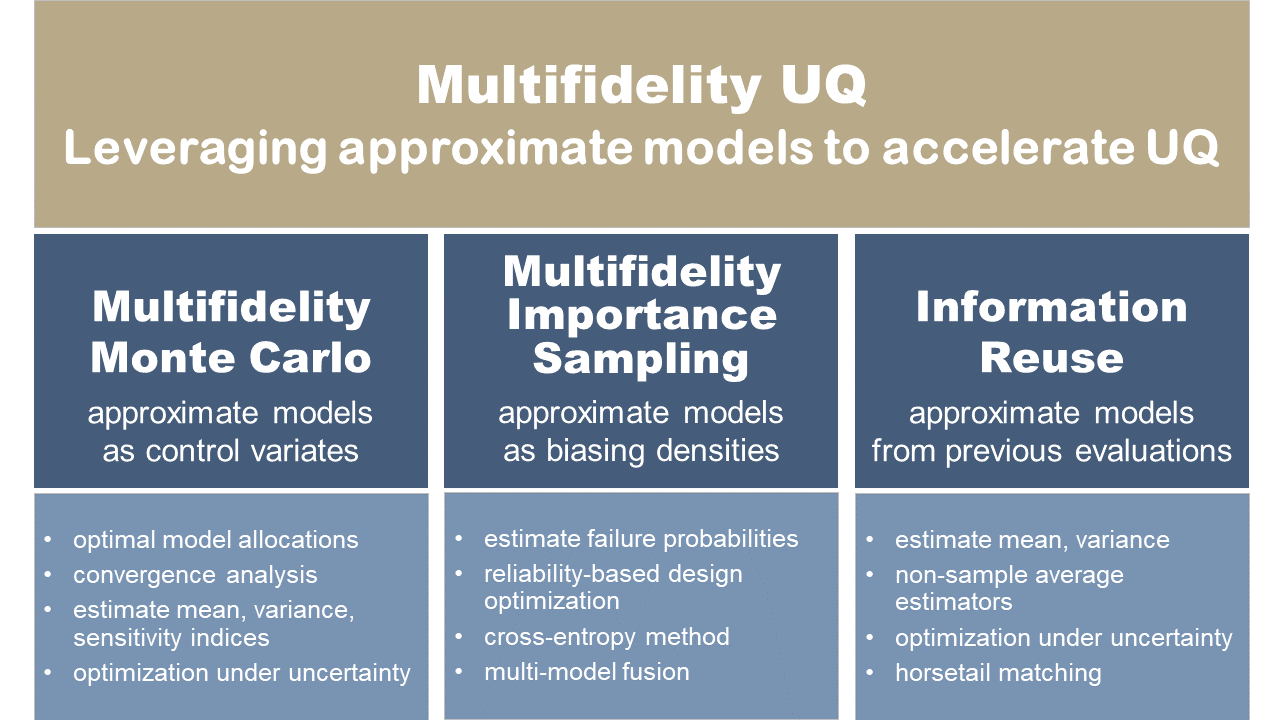
Our multifidelity UQ methods have three main approaches: (1) using approximate models as a control variate, (2) using approximate models as a biasing density, and (3) using old information as a source of approximate models.
Our work has developed methods for multifidelity uncertainty propagation, multifidelity failure probability estimation, multifidelity statistical inference, and multifidelity optimization under uncertainty.
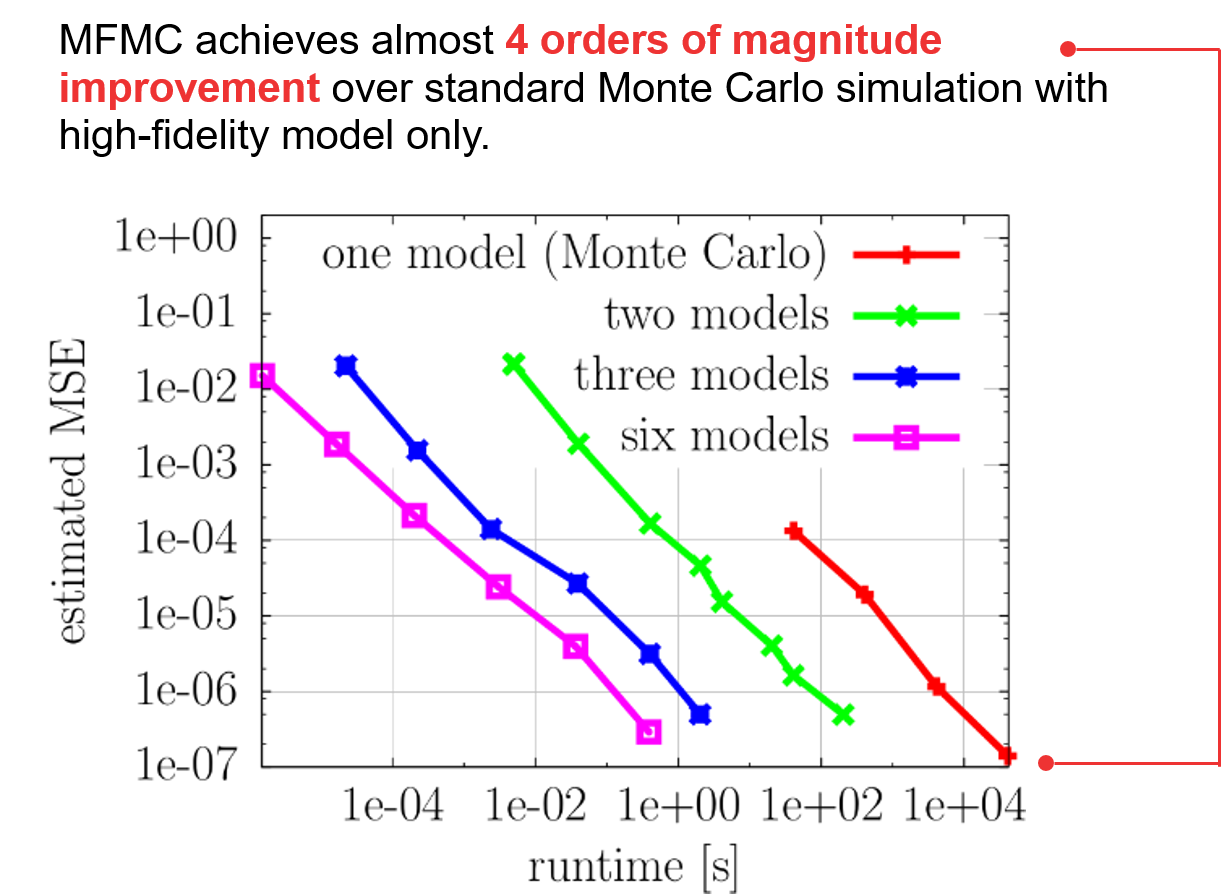
Our multifidelity Monte Carlo method uses a control variate formulation to accelerate the estimation of statistics of interest using multiple low-fidelity models.
These results in the mean squared error (MSE) of the estimated mean show that MFMC achieves almost 4 orders of magnitude improvement over standard Monte Carlo simulation with high-fidelity model only.
Relevant publications
Our multifidelity uncertainty propagation approach uses a control variate formulation to create the multifidelity Monte Carlo method (MFMC). The method has an optimal strategy for allocating evaluations among multiple models, so as to minimize the variance of the control variate estimator. Multi-level UQ methods (such as the multi-level Monte Carlo (MLMC) method) leverage hierarchies of models whose approximation qualities and costs are typically described with rates. Multi-level Monte Carlo uses these rates to distribute work among the models. Our multifidelity Monte Carlo method considers general low-fidelity models with properties that cannot necessarily be well described by rates.
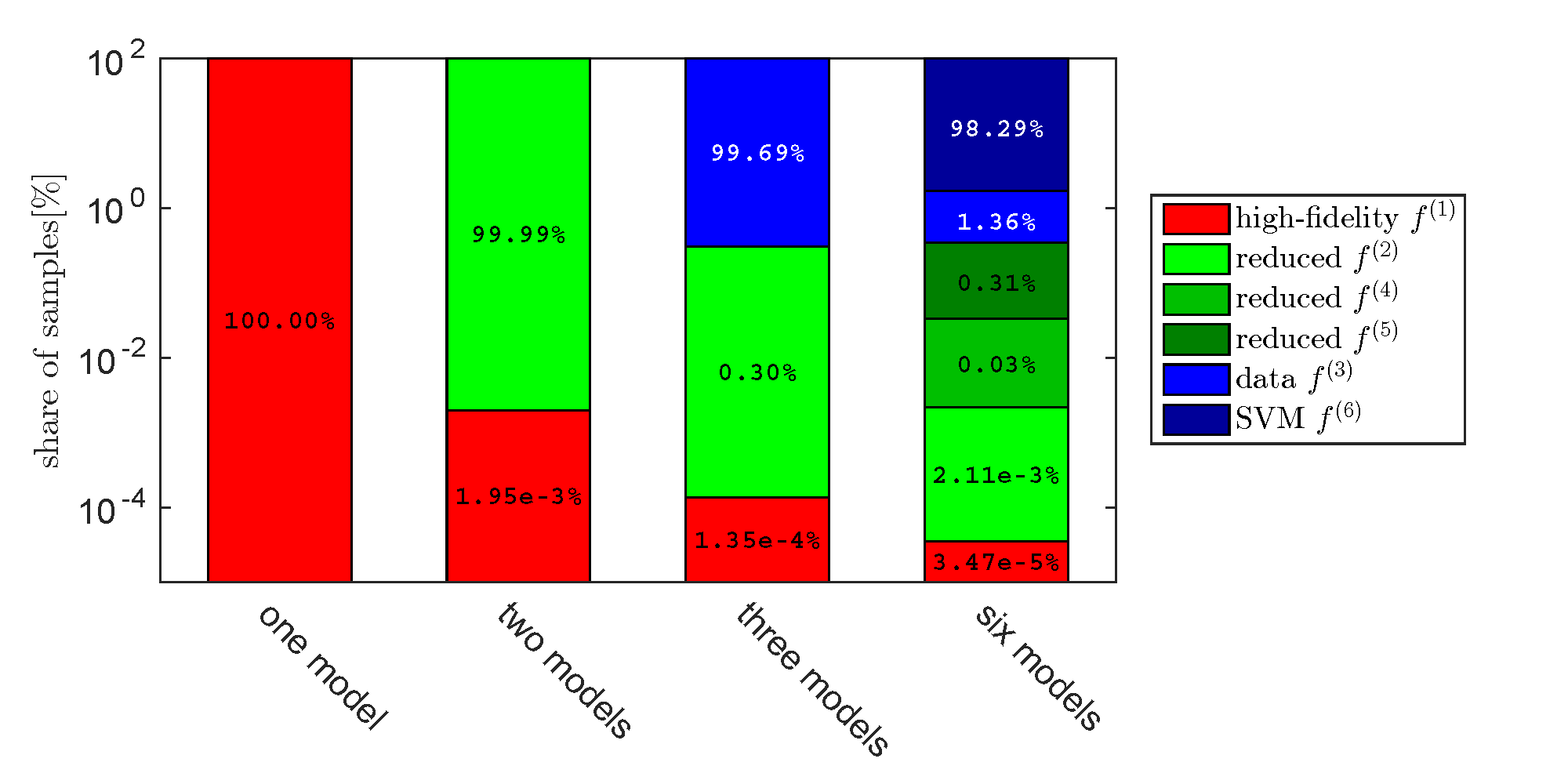
Our multifidelity Monte Carlo method optimally allocates evaluations among multiple models, so as to minimize estimator variance.
Download our open-source multi-fidelity Monte Carlo method repo at Github: Multifidelity Monte Carlo method codes. The repo includes Matlab codes that interface easily with your analysis models to determine the optimal ordering of the models and the optimal number of model evaluations. The repo also includes a simple example that demonstrates the methods and generates plots showing the results.
Our multifidelity global sensitivity analysis (MFGSA) method expands upon the MFMC control variate approach to accelerate the computation of variance and variance-based sensitivity indices. Sensitivity indices are used to quantify and rank the relative impact of uncertainty in different inputs on the output of a system, and are usually estimated using Monte Carlo sampling. Mean estimation using N Monte Carlo samples requires N function evaluations. However, estimating sensitivity indices for d parameters requires N(d+2) samples, which can lead to a much higher cost than in Monte Carlo uncertainty propagation. Our MFGSA method achieves speed-ups that allow different uncertainties to be definitively ranked with lower computational expenditure than high-fidelity global sensitivity analysis.
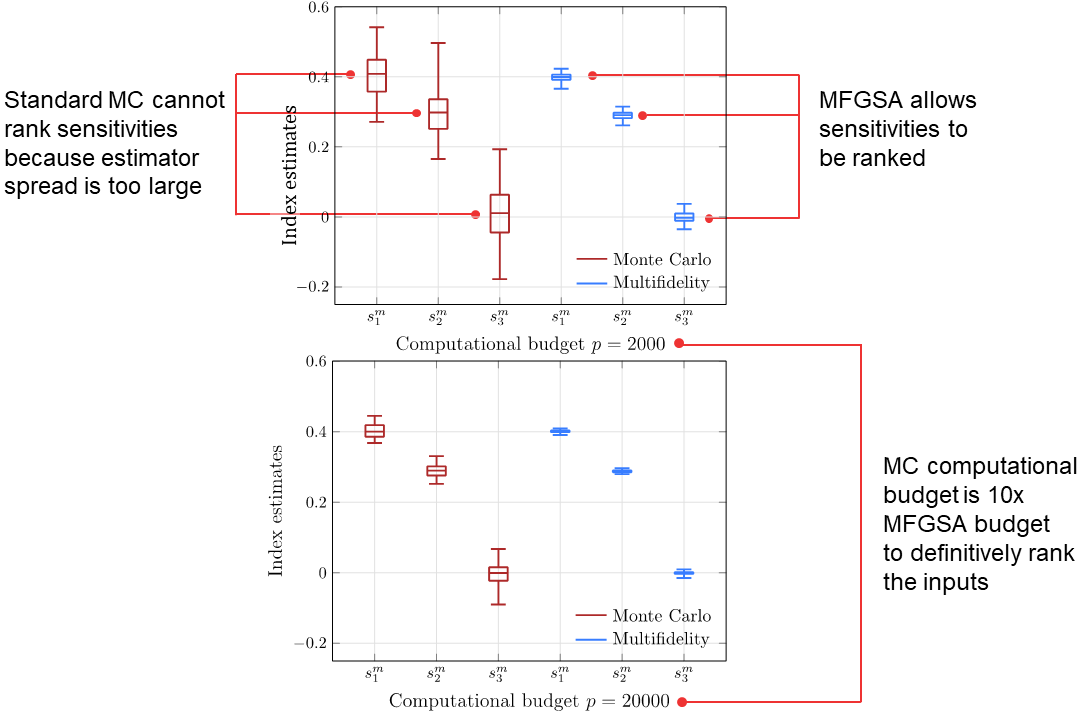
These results show that with a computational budget of 2000 high-fidelity model evaluations, Monte Carlo cannot definitively rank the impact of uncertainties in the three inputs for this example because the variance of the sensitivity index estimators is so large that their ranges overlap. Our MFGSA approach achieves estimators with small enough variances so that the ranges do not overlap with the same computational budget, allowing the inputs to be ranked in order of importance. The high-fidelity Monte Carlo method would require 20000 high-fidelity evaluations to rank the inputs, so our MFGSA approach achieves a 10x speed-up.
Like our multifidelity Monte Carlo method, our MFGSA framework can use general low-fidelity models of any form and does not require the approximation quality or costs of the low-fidelity model to be described with rates. The method can distribute work among models so that the MSE of the multifidelity variance estimator is minimized.
You can download our open source MFGSA code from GitHub: Multifidelity global sensitivity analysis codes. Our code interfaces easily with your analysis models and distributes work among them to estimate sensitivity indices and the variance.
Our multifidelity statistical inference approach uses a two-stage delayed acceptance Markov chain Monte Carlo (MCMC) formulation. A reduced order model is used in the first step of the two-stage MCMC method to increase the acceptance rate of candidates in the second step. In addition, the high-fidelity model outputs computed in the second step are used to adapt the reduced order model.
Our multifidelity optimization under uncertainty approach uses the control variate-based multifidelity Monte Carlo method embedded in an optimization loop. We show that the multi-fidelity information can come from a variety of information sources, including surrogate models, reduced order models, or past optimization iterations.
Peherstorfer, B., Willcox, K. and Gunzburger, M., SIAM Review, Vol. 60, No. 3, pp. 550-591, 2018.
In many situations across computational science and engineering, multiple computational models are available that describe a system of interest. These different models have varying evaluation costs and varying fidelities. Typically, a computationally expensive high-fidelity model describes the system with the accuracy required by the current application at hand, while lower-fidelity models are less accurate but computationally cheaper than the high-fidelity model. Outer-loop applications, such as optimization, inference, and uncertainty quantification, require multiple model evaluations at many different inputs, which often leads to computational demands that exceed available resources if only the high-fidelity model is used. This work surveys multifidelity methods that accelerate the solution of outer-loop applications by combining high-fidelity and low-fidelity model evaluations. The overall premise of these multifidelity methods is that low-fidelity models are leveraged for speedup while the high-fidelity model is kept in the loop to establish accuracy and/or convergence guarantees. We categorize multifidelity methods according to three classes of strategies: adaptation, fusion, and filtering. The paper reviews multifidelity methods in the outer-loop contexts of uncertainty propagation, inference, and optimization.
Qian, E., Peherstorfer, B., O'Malley, D., Vesselinov, V. and Willcox, K., SIAM/ASA Journal on Uncertainty Quantification, Vol. 6, Issue 2, pp. 683-706, 2018.
Variance-based sensitivity analysis provides a quantitative measure of how uncertainty in a model input contributes to uncertainty in the model output. Such sensitivity analyses arise in a wide variety of applications and are typically computed using Monte Carlo estimation, but the many samples required for Monte Carlo to be suffciently accurate can make these analyses intractable when the model is expensive. This work presents a multifidelity approach for estimating sensitivity indices that leverages cheaper low-fidelity models to reduce the cost of sensitivity analysis while retaining accuracy guarantees via recourse to the original, expensive model. This paper develops new multifidelity estimators for variance and for the Sobol' main and total effect sensitivity indices. We discuss strategies for dividing limited computational resources among models and specify a recommended strategy. Results are presented for the Ishigami function and a convection-diffusion- reaction model that demonstrate up to 10x speedups for fixed convergence levels. For the problems tested, the multifidelity approach allows inputs to be definitively ranked in importance when Monte Carlo alone fails to do so.
Heinkenschloss, M., Kramer, B., Takhtaganov, T. and Willcox, K., SIAM/ASA Journal on Uncertainty Quantification, Vol. 6, Issue 4, pp. 1395-1423, 2018.
This paper proposes and analyzes two reduced-order model (ROM) based approaches for the efficient and accurate evaluation of the Conditional-Value-at-Risk (CVaR) of quantities of interest (QoI) in engineering systems with uncertain parameters. CVaR is used to model objective or constraint functions in risk-averse engineering design and optimization applications under uncertainty. Evaluating the CVaR of the QoI requires sampling in the tail of the QoI distribution and typically requires many solutions of an expensive full-order model of the engineering system. Our ROM approaches substantially reduce this computational expense. Both ROM-based approaches use Monte Carlo (MC) sampling. The first approach replaces the computationally expensive full-order model by an inexpensive ROM. The resulting CVaR estimation error is proportional to the ROM error in the so-called risk region, a small region in the space of uncertain system inputs. The second approach uses a combination of full-order model and ROM evaluations via importance sampling, and is effective even if the ROM has large errors. In the importance sampling approach, ROM samples are used to estimate the risk region and to construct a biasing distribution. Few full-order model samples are then drawn from this biasing distribution. Asymptotically as the ROM error goes to zero, the importance sampling estimator reduces the variance by a factor $1-\beta \ll 1$, where $\beta \in (0,1)$ is the quantile level at which CVaR is computed. Numerical experiments on a system of semilinear convection-diffusion-reaction equations illustrate the performance of the approaches.
Cook, L.W., Jarrett, J.P., and Willcox, K., International Journal for Numerical Methods in Engineering, Volume 115, Issue 12, pp. 1457-1476, 2018.
In optimization under uncertainty for engineering design, the behavior of the system outputs due to uncertain inputs needs to be quantified at each optimization iteration, but this can be computationally expensive. Multi-fidelity techniques can significantly reduce the computational cost of Monte Carlo sampling methods for quantifying the effect of uncertain inputs, but existing multi-fidelity techniques in this context apply only to Monte Carlo estimators that can be expressed as a sample average, such as estimators of statistical moments. Information reuse is a particular multi-fidelity method that treats previous optimization iterations as lower-fidelity models. This work generalizes information reuse to be applicable to quantities with non-sample average estimators. The extension makes use of bootstrapping to estimate the error of estimators and the covariance between estimators at different fidelities. Specifically, the horsetail matching metric and quantile function are considered as quantities whose estimators are not sample- averages. In an optimization under uncertainty for an acoustic horn design problem, generalized information reuse demonstrated computational savings of over 60% compared to regular Monte Carlo sampling.
Peherstorfer, B., Kramer, B. and Willcox, K., SIAM/ASA Journal on Uncertainty Quantification, Vol. 6, No. 2, pp. 737-761, 2018.
Accurately estimating rare event probabilities with Monte Carlo can become costly if for each sample a computationally expensive high-fidelity model evaluation is necessary to approximate the system response. Variance reduction with importancesampling significantly reduces the number of required samples if a suitable biasing density is used. This work introduces a multifidelity approach that leverages a hierarchy of low-cost surrogate models to efficiently construct biasing densities for importance sampling. Our multifidelity approach is based on the cross-entropy method that derives a biasing density via an optimization problem. We approximate the solution of the optimization problem at each level of the surrogate-model hierarchy, reusing the densities found on the previous levels to precondition the optimization problem on the subsequent levels. With the preconditioning, an accurate approximation of the solution of the optimization problem at each level can be obtained from a few model evaluations only. In particular, at the highest level, only few evaluations of the computationally expensive high-fidelity model are necessary. Our numerical results demonstrate that our multifidelity approach achieves speedups of several orders of magnitude in a thermal and a reacting-flow example compared to the single-fidelity cross-entropy method that uses a single model alone.
Peherstorfer, B., Kramer, B. and Willcox, K., Journal of Computational Physics, 341:61-75, 2017.
In failure probability estimation, importance sampling constructs a biasing distribution that targets the failure event such that a small number of model evaluations is sufficient to achieve a Monte Carlo estimate of the failure probability with an acceptable accuracy; however, the construction of the biasing distribution often requires a large number of model evaluations, which can become computationally expensive. We present a mixed multifidelity importance sampling (MMFIS) approach that leverages computationally cheap but erroneous surrogate models for the construction of the biasing distribution and that uses the original high-fidelity model to guarantee unbiased estimates of the failure probability. The key property of our MMFIS estimator is that it can leverage multiple surrogate models for the construction of the biasing distribution, instead of a single surrogate model alone. We show that our MMFIS estimator has a mean-squared error that is up to a constant lower than the mean-squared errors of the corresponding estimators that uses any of the given surrogate models alone--even in settings where no information about the approximation qualities of the surrogate models is available. In particular, our MMFIS approach avoids the problem of selecting the surrogate model that leads to the estimator with the lowest mean-squared error, which is challenging if the approximation quality of the surrogate models is unknown. We demonstrate our MMFIS approach on numerical examples, where we achieve orders of magnitude speedups compared to using the high-fidelity model only.
Peherstorfer, B., Gunzburger, M., and Willcox, K., Numerische Mathematik, 139(3):683-707, 2018., https://doi.org/10.1007/s00211-018-0945-7.
The multifidelity Monte Carlo method provides a general framework for combining cheap low-fidelity approximations of an expensive high-fidelity model to accelerate the Monte Carlo estimation of statistics of the high-fidelity model output. In this work, we investigate the properties of multifidelity Monte Carlo estimation in the setting where a hierarchy of approximations can be constructed with known error and cost bounds. Our main result is a convergence analysis of multifidelity Monte Carlo estimation, for which we prove a bound on the costs of the multifidelity Monte Carlo estimator under assumptions on the error and cost bounds of the low-fidelity approximations. The assumptions that we make are typical in the setting of similar Monte Carlo techniques. Numerical experiments illustrate the derived bounds.
Peherstorfer, B., Willcox, K. and Gunzburger, M. SIAM Journal of Scientific Computing, Vol. 38, No. 5, pp. A3163-A3194, 2016.
This work presents an optimal model management strategy that exploits multifidelity surrogate models to accelerate the estimation of statistics of outputs of computationally expensive high-fidelity models. Existing acceleration methods typically exploit a multilevel hierarchy of surrogate models that follow a known rate of error decay and computational costs; however, a general collection of surrogate models, which may include projection-based reduced models, data-fit models, support vector machines, and simplified-physics models, does not necessarily give rise to such a hierarchy. Our multifidelity approach provides a framework to combine an arbitrary number of surrogate models of any type. Instead of relying on error and cost rates, an optimization problem balances the number of model evaluations across the high-fidelity and surrogate models with respect to error and costs. We show that a unique analytic solution of the model management optimization problem exists under mild conditions on the models. Our multifidelity method makes occasional recourse to the high-fidelity model; in doing so it provides an unbiased estimator of the statistics of the high-fidelity model, even in the absence of error bounds and error estimators for the surrogate models. Numerical experiments with linear and nonlinear examples show that speedups by orders of magnitude are obtained compared to Monte Carlo estimation that invokes a single model only.
Kramer, B., Marques, A., Peherstorfer, B., Villa, U. and Willcox, K., ACDL TR-2017-3, Submitted, 2017
This paper develops a multifidelity method that enables estimation of failure probabilities for expensive-to-evaluate models via a new combination of techniques, drawing from information fusion and importance sampling. We use low-fidelity models to derive biasing densities for importance sampling and then fuse the importance sampling estimators such that the fused multifidelity estimator is unbiased and has mean-squared error lower than or equal to that of any of the importance sampling estimators alone. The presented general fusion method combines multiple probability estimators with the goal of further variance reduction. By fusing all available estimators, the method circumvents the challenging problem of selecting the best biasing density and using only that density for sampling. A rigorous analysis shows that the fused estimator is optimal in the sense that it has minimal variance amongst all possible combinations of the estimators. The asymptotic behavior of the proposed method is demonstrated on a convection-diffusion-reaction PDE model for which n=1.e5 samples can be afforded. To illustrate the proposed method at scale, we consider a model of a free plane jet and quantify how uncertainties at the flow inlet propagate to a quantity of interest related to turbulent mixing. The computed fused estimator has similar root-mean-squared error to that of an importance sampling estimator using a density computed from the high-fidelity model. However, it reduces the CPU time to compute the biasing density from 2.5 months to three weeks.
Ng, L. and Willcox, K. International Journal for Numerical Methods in Engineering, Volume 100 Issue 10, pp. 746-772, published online 17 September, 2014, DOI: 10.1002/nme.4761.
It is important to design robust and reliable systems by accounting for uncertainty and variability in the design process. However, performing optimization in this setting can be computationally expensive, requiring many evaluations of the numerical model to compute statistics of the system performance at every optimization iteration. This paper proposes a multifidelity approach to optimization under uncertainty that makes use of inexpensive, low-fidelity models to provide approximate information about the expensive, high-fidelity model. The multifidelity estimator is developed based on the control variate method to reduce the computational cost of achieving a specified mean square error in the statistic estimate. The method optimally allocates the computational load between the two models based on their relative evaluation cost and the strength of the correlation between them. This paper also develops an information reuse estimator that exploits the autocorrelation structure of the high-fidelity model in the design space to reduce the cost of repeatedly estimating statistics during the course of optimization. Finally, a combined estimator incorporates the features of both the multifidelity estimator and the information reuse estimator. The methods demonstrate 90% computational savings in an acoustic horn robust optimization example and practical design turnaround time in a robust wing optimization problem.
Ng, L. and Willcox, K. AIAA Journal of Aircraft, Vol. 53, No. 2, pp. 427-438, 2016.
This paper develops a multi-information source formulation for aerospace design under uncertainty problems. As a specific demonstration of the approach, it presents the optimization under uncertainty of an advanced subsonic transport aircraft developed to meet the NASA N+3 goals, and shows how the multi-information source approach enables practical turnaround time for this conceptual aircraft optimization under uncertainty problem. In the conceptual design phase, there are often uncertainties about future developments of the underlying technologies. An aircraft design that is robust to uncertainty is more likely to meet performance requirements as the technologies mature in the intermediate and detailed design phases, reducing the need for expensive redesigns. In the particular example selected here to present the new approach, the multi-information source approach uses an information-reuse estimator that takes advantage of the correlation of the aircraft model in the design space to reduce the number of model evaluations needed to achieve a given standard error in the Monte Carlo estimates of the relevant design statistics (mean and variance). Another contribution of the paper is to extend the approach to reuse information during trade studies that involve solving multiple optimization under uncertainty problems, enabling the analysis of the risk-performance trade-off in optimal aircraft designs.
Cui, T., Marzouk, Y. and Willcox, K. International Journal for Numerical Methods in Engineering, Vol. 102, No. 5, pp. 966-990, published online 15 August, 2014, DOI: 10.1002/nme.4748.
One of the major challenges in the Bayesian solution of inverse problems governed by partial differential equations (PDEs) is the computational cost of repeatedly evaluating numerical PDE models, as required by Markov chain Monte Carlo (MCMC) methods for posterior sampling. This paper proposes a data-driven projection-based model reduction technique to reduce this computational cost. The proposed technique has two distinctive features. First, the model reduction strategy is tailored to inverse problems: the snapshots used to construct the reduced-order model are computed adaptively from the posterior distribution. Posterior exploration and model reduction are thus pursued simultaneously. Second, to avoid repeated evaluations of the full-scale numerical model as in a standard MCMC method, we couple the full-scale model and the reduced-order model together in the MCMC algorithm. This maintains accurate inference while reducing its overall computational cost. In numerical experiments considering steady-state flow in a porous medium, the data-driven reduced-order model achieves better accuracy than a reduced-order model constructed using the classical approach. It also improves posterior sampling efficiency by several orders of magnitude compared with a standard MCMC method.